原文链接:Laravel HorizonとLaravel Telescopeでできること オープンロジにおけるQueueの運用管理 ,扫盲向而且挺实用,转载过来记录几个要点。
PPT地址: https://cdn.kelu.org/blog/2020/06/20190318-Laravue8-OPENLOGI.pdf
大家好,我是Open Logic的Igarashi。关于Vue和前台的大家讨论了很多,接下来我谈谈服务器端。
上个月我在 OpenLogi 的 Laravel 分享会中谈到 “Laravel 队列操作与管理”,今天我就这个话题进一步展开。

首先做个自我介绍…// (介绍他们公司的,主要做物流的,就不转了。)

我们的技术栈去年有分享过,在Qiita上可以找到。简单来说,服务器端是Laravel,前端是React。我将Vue用于新产品。
job 基础
20多年前,Bertrand Meyer在他的《Object-Oriented Software Construction》一书中提出了CQS(Command Query Seperation,命令查询分离)的概念,后来,Greg Young在此基础上提出了CQRS(Command Query Resposibility Segregation,命令查询职责分离),将CQS的概念从方法层面提升到了模型层面,即“命令”和“查询”分别使用不同的对象模型来表示。
采用CQRS的驱动力除了从CQS那里继承来的好处之外,还旨在解决软件中日益复杂的查询问题,比如有时我们希望从不同的维度查询数据,或者需要将各种数据进行组合后返回给调用方。此时,将查询逻辑与业务逻辑糅合在一起会使软件迅速腐化,诸如逻辑混乱、可读性变差以及可扩展性降低等等一些列问题。
对于Web应用程序,处理中要做的主要事情是读取或写入信息。

上图是一个简单的配置,读取意味着通过Web服务器从数据库读取数据并将结果返回给客户端。
如果有要写入的内容,则可以通过POST等方法通过Web服务器将其写入数据库,如果成功,则将结果返回给客户端。
原则上,我们不应在同一台Web服务器上进行读写。做到这一点的方法是利用工作。首先,以Command 的形式将其扔到 Web 服务器。Web 服务器将其加入队列。然后,执行可变处理的作业服务器使队列出队并执行写处理。

将结果返回给客户端的方式有很多种选择,可以使用Pusher 和 Redis。我们使用 Pusher 来实现。即使 Pusher 服务器不同,也可以正确地异步发送反馈。
看起来非常困难,但是由于Laravel从一开始就考虑到DDD和CQRS的设计,因此实现起来非常容易。

在Controller上有一个方法,例如 updateItem,CQRS 的做法就是创建一个名为updateItem的作业并将其分派。
job的状态管理

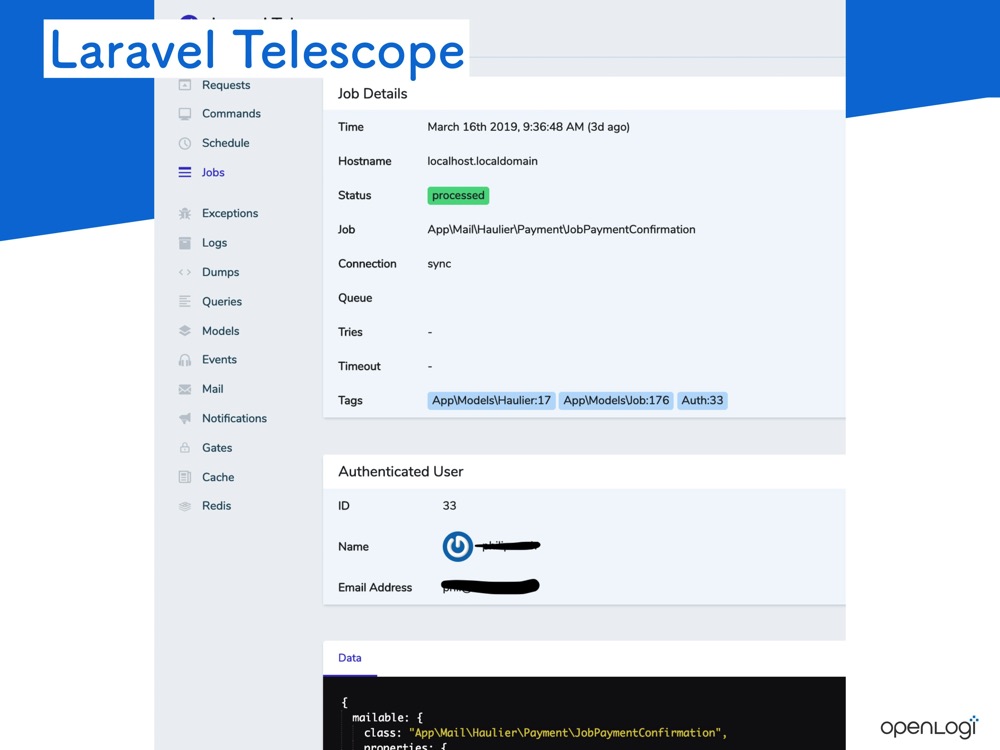
这是 Laravel Horizon和Laravel Telescope。 它们很相似。

Telescope 是一个开发调试工具,用于了解 Laravel 中的状态。虽然我们有了 Laravel Debugbar 这样的工具用于开发,但是 Laravel 中会发生各种事件,例如请求,查询和作业状态以及通知事件的结果,Telescope 可以将这些状态集中起来看。
从这里可以看到,有各种参数,例如Exception,log,query,model,event等。
Horizon 是用于生产环境的监视工具,而 Telescope 是用于给开发人员使用的工具。
两者都支持队列,不过 Horizon 仅支持 Redis。Telescope 不仅限于Redis,它还支持 DB 队列、SQS队列,并且可以看到所有同步作业的状态。
Horizon 主要是用于调试和监视。

如上图,在OpenLogi中,我们单独记录了job的状态,通过将所有更新处理整合到job中来,我们还可以跟踪谁进行了什么操作以及何时进行。

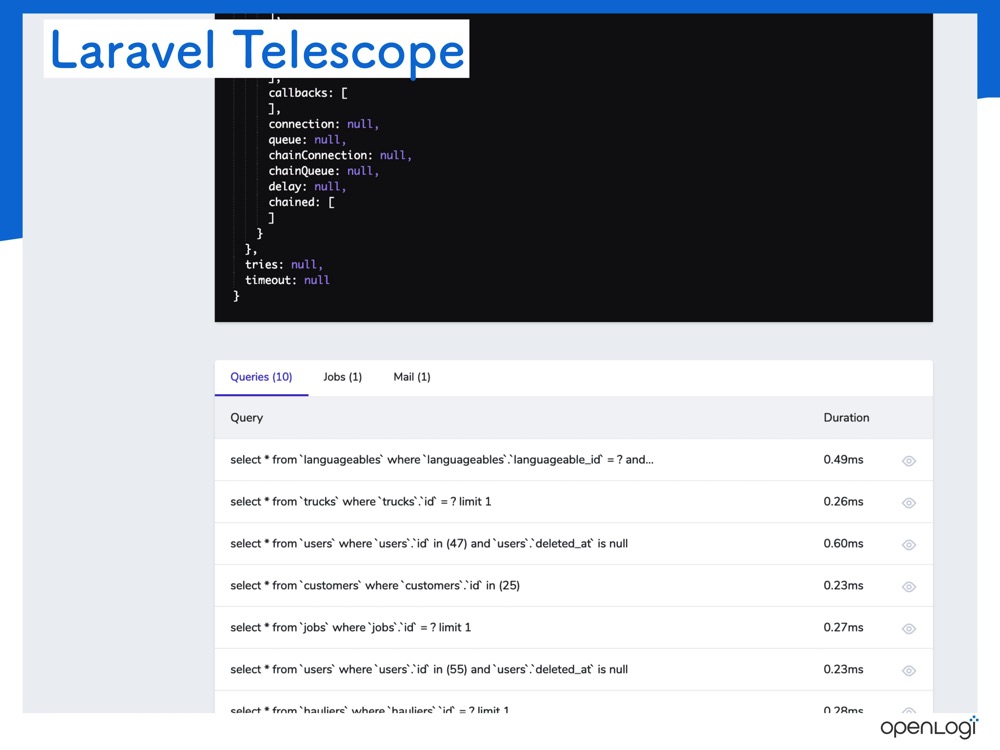
Telescope 也做了类似的事情,它会记录用户使用哪些参数运行的作业。这种记录会增加数据库的负担,不过它仅用于调试,线上不运行,但这是我想要的。

您可以看到针对查询,职位和电子邮件发出了什么样的查询,因此我认为这对开发很有用。
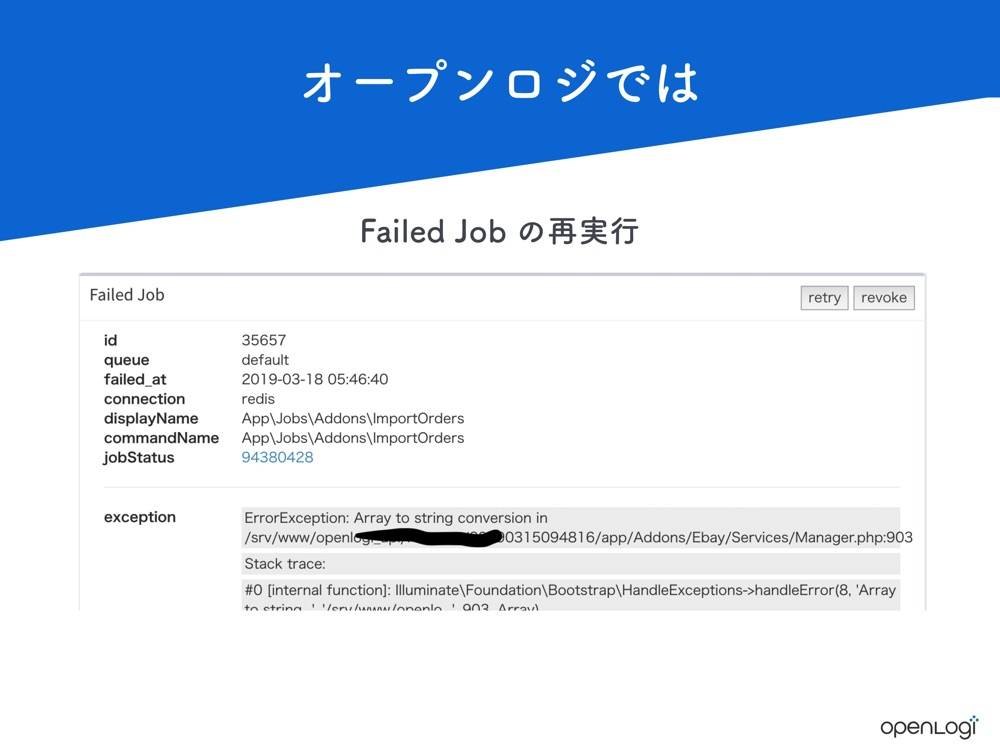
重新执行失败的作业也是操作中的常见情况。


关于这一点,Laravel Horizon 中有一个类似的页面,但是我们在Horizon 之前就设计了这类工具。

我需要像 Horizon 这样的监视工具,但同时我也希望能够像 Telescope 这样正确地记录日志,有点鱼和熊掌不可得兼的感觉。我正在寻找一种可以管理的工具,但是现在我们打算自己实现它。
总结